
개발 창고
운영체제 교착 상태(Deadlock) 완전 분석 본문
교착 상태의 개념과 정의
교착 상태(Deadlock)는 멀티프로세싱 환경에서 두 개 이상의 프로세스가 서로가 점유한 자원을 기다리며 무한 대기 상태에 빠지는 현상입니다. 이는 시스템의 진행을 완전히 멈추게 하는 심각한 문제로, 운영체제 설계에서 반드시 고려해야 할 핵심 요소입니다.
교착 상태가 발생하면 관련된 모든 프로세스가 실행을 계속할 수 없게 되며, 외부의 개입 없이는 자연적으로 해결되지 않습니다. 이는 시스템 자원의 비효율적 사용과 성능 저하를 초래하며, 심각한 경우 시스템 전체의 마비를 야기할 수 있습니다.
교착 상태 발생의 필요충분조건
교착 상태가 발생하기 위해서는 다음 네 가지 조건이 동시에 성립해야 합니다. 이러한 조건들을 Coffman 조건이라고도 합니다.
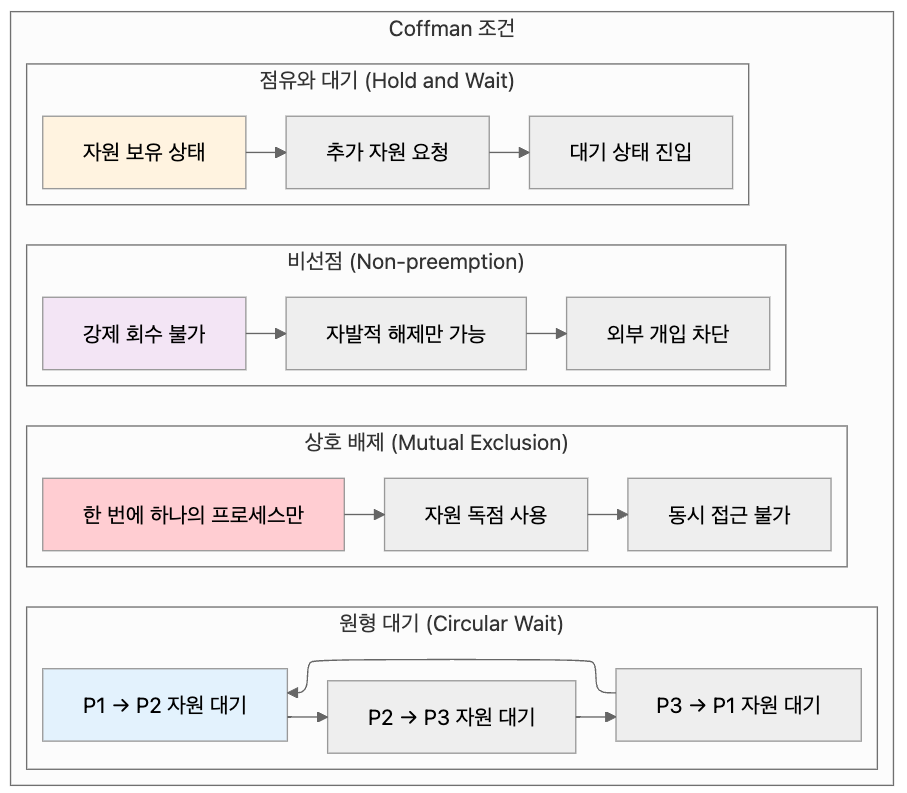
상호 배제 (Mutual Exclusion)
한 번에 하나의 프로세스만이 특정 자원을 사용할 수 있는 조건입니다. 자원이 배타적으로 할당되어 다른 프로세스가 동시에 접근할 수 없을 때 성립합니다. 예를 들어, 프린터나 파일과 같은 자원은 일반적으로 상호 배제 특성을 가집니다.
점유와 대기 (Hold and Wait)
프로세스가 최소 하나의 자원을 점유한 상태에서 다른 프로세스가 점유한 추가 자원을 기다리는 조건입니다. 이 조건에서 프로세스는 이미 할당받은 자원을 유지하면서 동시에 새로운 자원을 요청합니다.
비선점 (Non-preemption)
이미 할당된 자원을 강제로 빼앗을 수 없는 조건입니다. 자원을 점유한 프로세스만이 자발적으로 해당 자원을 해제할 수 있으며, 운영체제나 다른 프로세스가 강제로 자원을 회수할 수 없습니다.
원형 대기 (Circular Wait)
프로세스들이 원형으로 연결되어 각각 다음 프로세스가 점유한 자원을 기다리는 조건입니다. 프로세스 P1이 P2의 자원을, P2가 P3의 자원을, 최종적으로 Pn이 P1의 자원을 기다리는 형태의 순환 구조가 형성됩니다.
교착 상태 해결 전략
교착 상태를 다루는 방법은 크게 네 가지 접근법으로 분류됩니다.
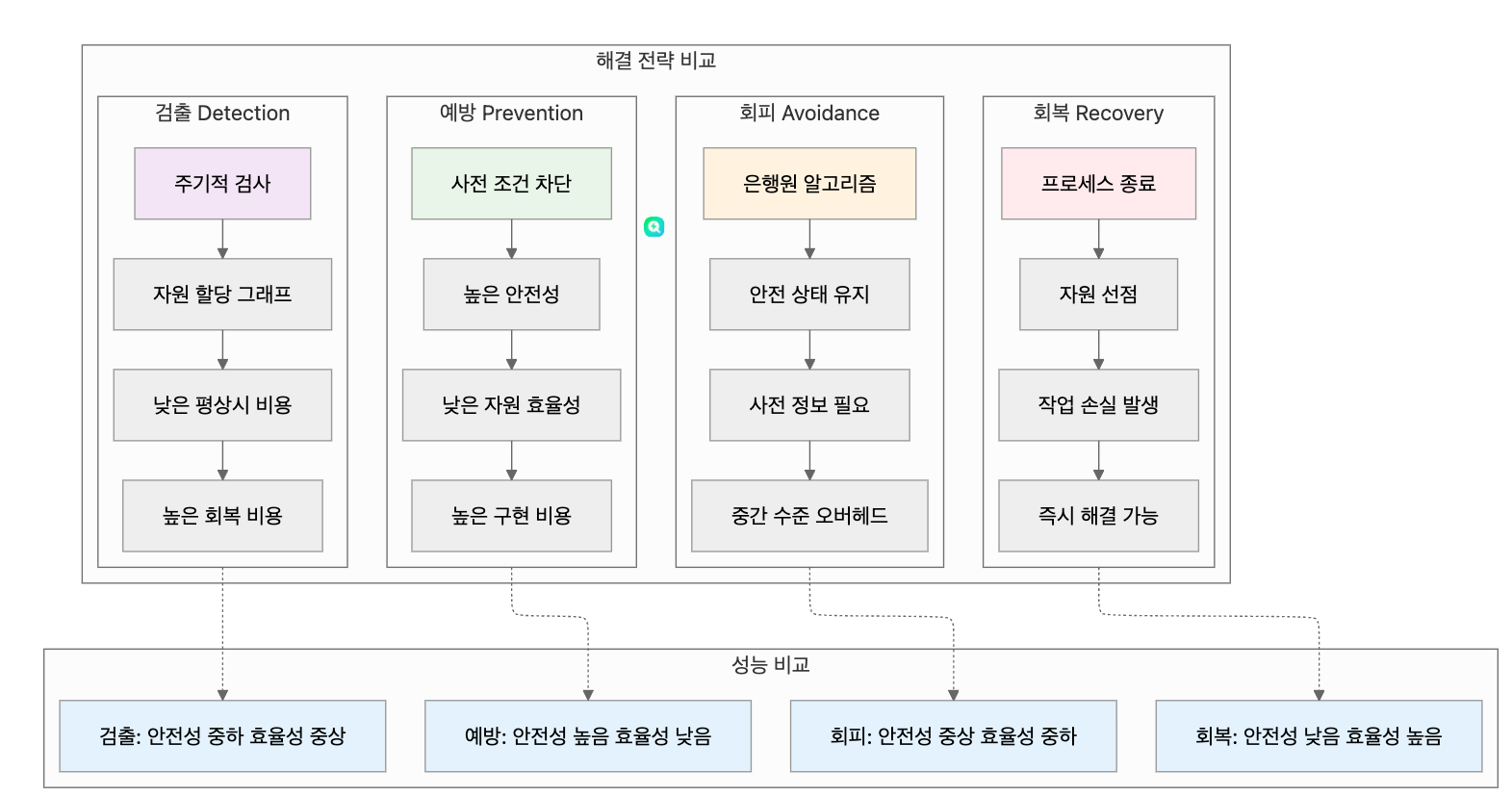
예방 (Prevention)
교착 상태의 발생 조건 중 하나 이상을 원천적으로 차단하여 교착 상태가 발생할 가능성을 배제하는 방법입니다.
상호 배제 조건 제거 가능한 한 자원을 공유 가능하게 만드는 방법입니다. 그러나 프린터, 파일 등 본질적으로 공유할 수 없는 자원에는 적용하기 어렵습니다.
점유와 대기 조건 제거
// 모든 자원을 한 번에 요청하는 방식
int request_all_resources(process_t *proc, resource_t resources[], int count) {
// 모든 자원이 사용 가능한지 확인
for (int i = 0; i < count; i++) {
if (!is_available(resources[i])) {
return FAILURE;
}
}
// 모든 자원을 한 번에 할당
for (int i = 0; i < count; i++) {
allocate_resource(proc, resources[i]);
}
return SUCCESS;
}
비선점 조건 제거 자원을 강제로 회수할 수 있도록 하는 방법입니다. 그러나 이는 프로세스의 일관성을 해칠 수 있어 신중한 구현이 필요합니다.
원형 대기 조건 제거 자원에 순서를 부여하고 항상 증가하는 순서로만 자원을 요청하도록 하는 방법입니다.
// 자원 순서화 예시
#define RESOURCE_DISK 1
#define RESOURCE_PRINTER 2
#define RESOURCE_NETWORK 3
int ordered_resource_request(process_t *proc, int resource_type) {
if (resource_type <= proc->last_allocated_resource) {
return INVALID_ORDER;
}
if (allocate_resource(proc, resource_type)) {
proc->last_allocated_resource = resource_type;
return SUCCESS;
}
return FAILURE;
}
회피 (Avoidance)
시스템이 안전한 상태를 유지할 수 있는 경우에만 자원을 할당하는 방법입니다. 가장 널리 알려진 회피 알고리즘은 은행원 알고리즘(Banker's Algorithm)입니다.
// 은행원 알고리즘 구현 예시
typedef struct {
int allocation[MAX_PROCESSES][MAX_RESOURCES];
int max_need[MAX_PROCESSES][MAX_RESOURCES];
int available[MAX_RESOURCES];
int need[MAX_PROCESSES][MAX_RESOURCES];
} banker_state_t;
bool is_safe_state(banker_state_t *state, int processes, int resources) {
bool finished[MAX_PROCESSES] = {false};
int work[MAX_RESOURCES];
// 사용 가능한 자원으로 초기화
for (int i = 0; i < resources; i++) {
work[i] = state->available[i];
}
// 안전 순서 찾기
int count = 0;
while (count < processes) {
bool found = false;
for (int p = 0; p < processes; p++) {
if (!finished[p]) {
bool can_finish = true;
// 필요한 자원이 사용 가능한지 확인
for (int r = 0; r < resources; r++) {
if (state->need[p][r] > work[r]) {
can_finish = false;
break;
}
}
if (can_finish) {
// 프로세스 완료 처리
for (int r = 0; r < resources; r++) {
work[r] += state->allocation[p][r];
}
finished[p] = true;
found = true;
count++;
}
}
}
if (!found) {
return false; // 불안전한 상태
}
}
return true; // 안전한 상태
}
검출 (Detection)
교착 상태의 발생을 허용하되, 주기적으로 교착 상태를 탐지하는 방법입니다. 자원 할당 그래프를 이용한 검출이 일반적입니다.
// 자원 할당 그래프를 이용한 교착 상태 검출
typedef struct edge {
int from;
int to;
struct edge *next;
} edge_t;
typedef struct {
edge_t *edges[MAX_NODES];
bool visited[MAX_NODES];
bool in_stack[MAX_NODES];
} graph_t;
bool has_cycle(graph_t *graph, int node, int node_count) {
graph->visited[node] = true;
graph->in_stack[node] = true;
edge_t *current = graph->edges[node];
while (current != NULL) {
int neighbor = current->to;
if (graph->in_stack[neighbor]) {
return true; // 사이클 발견
}
if (!graph->visited[neighbor] && has_cycle(graph, neighbor, node_count)) {
return true;
}
current = current->next;
}
graph->in_stack[node] = false;
return false;
}
bool detect_deadlock(graph_t *graph, int node_count) {
// 모든 노드 초기화
for (int i = 0; i < node_count; i++) {
graph->visited[i] = false;
graph->in_stack[i] = false;
}
// 각 노드에서 사이클 검사
for (int i = 0; i < node_count; i++) {
if (!graph->visited[i]) {
if (has_cycle(graph, i, node_count)) {
return true;
}
}
}
return false;
}
회복 (Recovery)
교착 상태가 검출된 후 이를 해결하는 방법입니다. 주요 회복 기법은 다음과 같습니다.
프로세스 종료
- 교착 상태에 있는 모든 프로세스 종료
- 교착 상태가 해결될 때까지 하나씩 순차적으로 종료
자원 선점
- 희생자 선택: 비용이 최소인 프로세스 선택
- 롤백: 프로세스를 안전한 상태로 되돌림
- 기아 방지: 같은 프로세스가 계속 희생자가 되지 않도록 보장
// 프로세스 종료를 통한 회복
typedef struct {
int process_id;
int priority;
int execution_time;
int allocated_resources[MAX_RESOURCES];
} process_info_t;
int select_victim(process_info_t processes[], int count) {
int victim = 0;
int min_cost = calculate_termination_cost(&processes[0]);
for (int i = 1; i < count; i++) {
int cost = calculate_termination_cost(&processes[i]);
if (cost < min_cost) {
min_cost = cost;
victim = i;
}
}
return victim;
}
int calculate_termination_cost(process_info_t *process) {
// 실행 시간, 우선순위, 할당된 자원 등을 고려한 비용 계산
return process->execution_time * process->priority +
count_allocated_resources(process);
}
실무에서의 교착 상태 관리
데이터베이스 시스템에서의 교착 상태
데이터베이스 관리 시스템은 트랜잭션 간의 락 경합으로 인한 교착 상태를 자주 경험합니다.
-- 교착 상태 발생 예시
-- 트랜잭션 1
BEGIN TRANSACTION;
UPDATE accounts SET balance = balance - 100 WHERE id = 1;
-- 트랜잭션 2가 실행되기를 기다림
UPDATE accounts SET balance = balance + 100 WHERE id = 2;
COMMIT;
-- 트랜잭션 2 (동시 실행)
BEGIN TRANSACTION;
UPDATE accounts SET balance = balance - 50 WHERE id = 2;
-- 트랜잭션 1이 실행되기를 기다림
UPDATE accounts SET balance = balance + 50 WHERE id = 1;
COMMIT;
이를 해결하기 위한 방법:
-- 자원 순서화를 통한 교착 상태 방지
BEGIN TRANSACTION;
UPDATE accounts SET balance = balance - 100 WHERE id = LEAST(from_id, to_id);
UPDATE accounts SET balance = balance + 100 WHERE id = GREATEST(from_id, to_id);
COMMIT;
분산 시스템에서의 교착 상태
분산 환경에서는 네트워크 지연과 부분 실패로 인해 교착 상태 처리가 더욱 복잡해집니다. 분산 교착 상태 검출을 위해서는 글로벌 대기 그래프(Global Wait Graph)를 구성해야 합니다.
성능과 안정성 고려사항
교착 상태 방지 비용
각 교착 상태 해결 방법은 서로 다른 성능 특성을 보입니다:
- 예방: 높은 안전성, 낮은 자원 활용률
- 회피: 중간 정도의 오버헤드, 사전 정보 필요
- 검출 및 회복: 낮은 평상시 오버헤드, 높은 회복 비용
실시간 시스템에서의 고려사항
실시간 시스템에서는 교착 상태로 인한 지연이 치명적일 수 있습니다. 따라서 예방 또는 회피 방법을 선호하며, 검출과 회복은 예측 가능한 시간 내에 완료되어야 합니다.
모니터링과 디버깅
교착 상태 모니터링 도구
# Linux에서 프로세스 락 상태 확인
lsof -p PID | grep LOCK
cat /proc/locks
# 데이터베이스 교착 상태 모니터링 (PostgreSQL)
SELECT * FROM pg_locks WHERE NOT granted;
# Java 애플리케이션 교착 상태 검출
jstack PID | grep -A 5 "Found Java-level deadlock"
로깅과 분석
교착 상태 발생 시 상세한 로그 정보 수집이 중요합니다:
void log_deadlock_detection(process_info_t involved_processes[], int count) {
fprintf(log_file, "DEADLOCK DETECTED at %ld\n", time(NULL));
fprintf(log_file, "Involved processes: ");
for (int i = 0; i < count; i++) {
fprintf(log_file, "PID=%d (waiting for resource %d), ",
involved_processes[i].process_id,
involved_processes[i].waiting_resource);
}
fprintf(log_file, "\nResource allocation state:\n");
print_resource_allocation_table();
}
결론
교착 상태는 멀티프로세싱 시스템에서 피할 수 없는 문제이지만, 적절한 설계와 구현을 통해 효과적으로 관리할 수 있습니다. 시스템의 특성과 요구사항에 따라 예방, 회피, 검출, 회복 중 적절한 전략을 선택하는 것이 중요합니다.
현대의 복잡한 분산 시스템에서는 다양한 수준에서 교착 상태가 발생할 수 있으므로, 설계 단계부터 교착 상태를 고려한 아키텍처를 구성하고 지속적인 모니터링을 통해 시스템의 안정성을 확보해야 합니다.
참고 자료
- "Operating System Concepts" - Abraham Silberschatz
- "Modern Operating Systems" - Andrew S. Tanenbaum
- PostgreSQL Documentation - Lock Monitoring
- Java Concurrency Documentation - Deadlock Detection
- Linux Kernel Documentation - Locking Mechanisms